kyudobot
Intro
This is a line bot for analyzing kyudou practice, using AWS+LINEAPI
Sources
AWS console
LINEBOT_LINK=https://lin.ee/ZyrxxzG
DOCUMENTS
箭矢落點辨識結合LINE聊天機器人自動化分析
壹、摘要
一、 啟發 鑒於平時有在進行弓道運動時,經常遇到需要記錄練習情況卻苦於沒有合適的軟體與方式,而現今記錄冊也大多只有中靶率及手動輸入落點的功能,在大量練習的過程中,有時僅是以相機匆匆記錄下上靶情況,事後也鮮少從相簿中翻出整理,因此利用本次期末專題的時機,決意自行開發一個易於使用且方便快速的分析記錄。 二、 預期效果-LINE 在考慮到自身使用習慣、直覺程度以及便利性決定使用LINE BOT 作為接口進行開發,便於及時收發訊息與傳遞文字與圖片。在實際射箭的場景中,由於取箭速度較快,不一定有時間慢慢記錄下中靶情況,有時即使手機拍了也會忘了記錄下,期待在使用了LINEBOT後直接拍照上傳,便可以更好的記錄下練習情況。
貳、 開發過程與專案架構
一、 專案架構 本次專案的架構是以LINE的聊天機器人LINE BOT SDK模組進行開發,負責處理使用者交談互動與引導以及與資料處理流程的邏輯橋接,而後端開發則串接了AWS 的無伺服器服務lambda和API Gateway來進行路由提供服務。
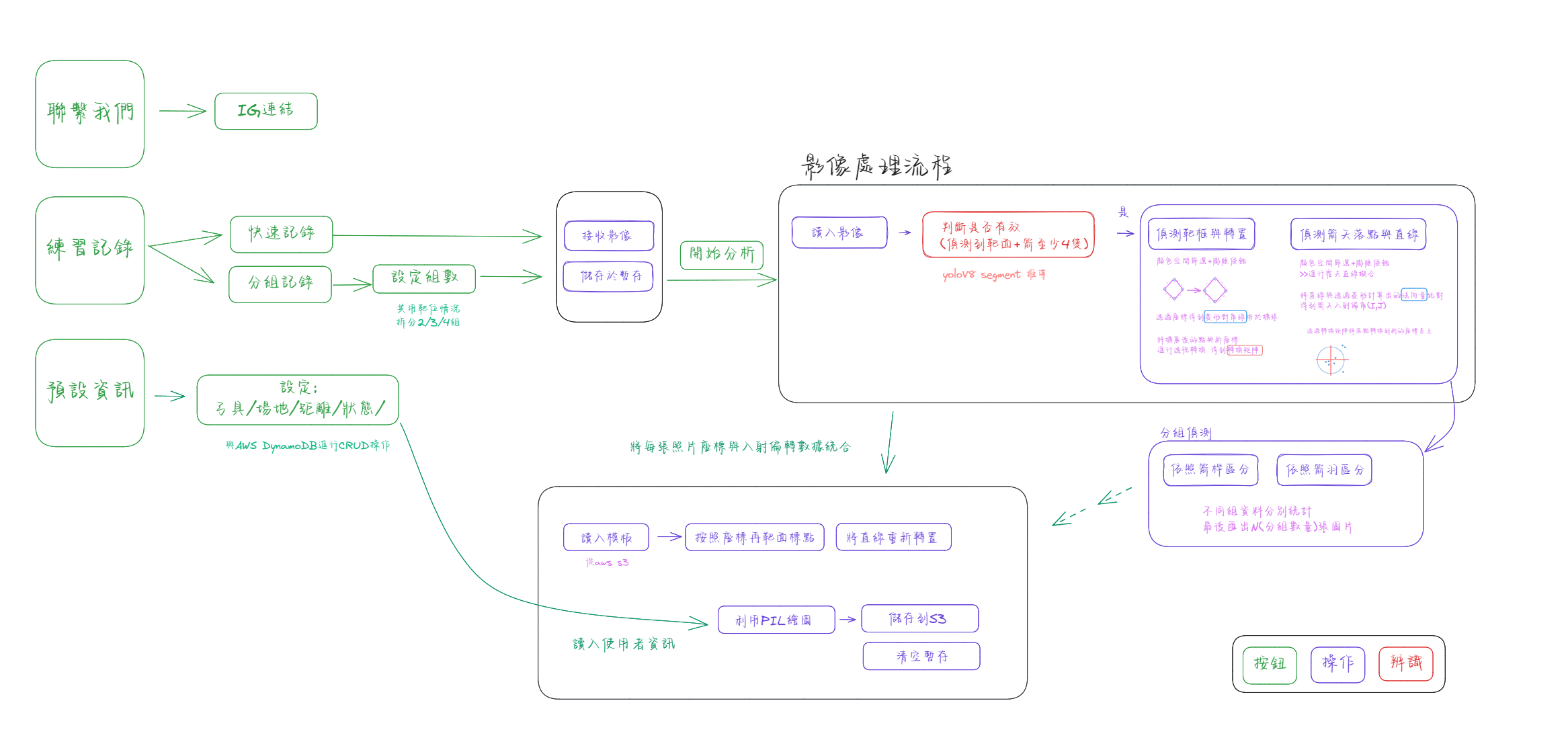 (圖一、程式流程圖)
(圖一、程式流程圖)
由上圖一可見LINE BOT提供的功能主要分成三類,聯繫客服、設定預設資料以及本次專題的主軸-練習記錄。透過python撰寫LINEBOT回應順序與錯誤處理,也使用了不同的訊息模式比如快速回復與文字按鈕來增加使用的便利性。
二、 影像處理 在使用者傳送完圖片輸入”開始分析”或是達到支援上限的十張照片時,程式會將儲存到AWS S3的照片依次載入處理程序處理特徵與提取資料,最後將特徵資料匯整進行資料繪圖
甲、 圖片可用性預判—Yolov8 segmentation 在圖片進入程式開始提取特徵前,我們先使用了以自己以yolov8訓練的模型快速檢驗了圖片的可用性。模型的部分我們首先利用Rainbo平台針對不同場景的照片進行手動標註,透過多邊形圈選箭矢本身,而後利用旋轉、透視、鏡像等方式將原先46張的資料集訓練集擴充成710張圖片,並且分成650張訓練,41張驗證,19張測試。
 (圖二、框選預覽)
(圖二、框選預覽)
 (圖三、經由200次Epoch之訓練成果)
(圖三、經由200次Epoch之訓練成果)
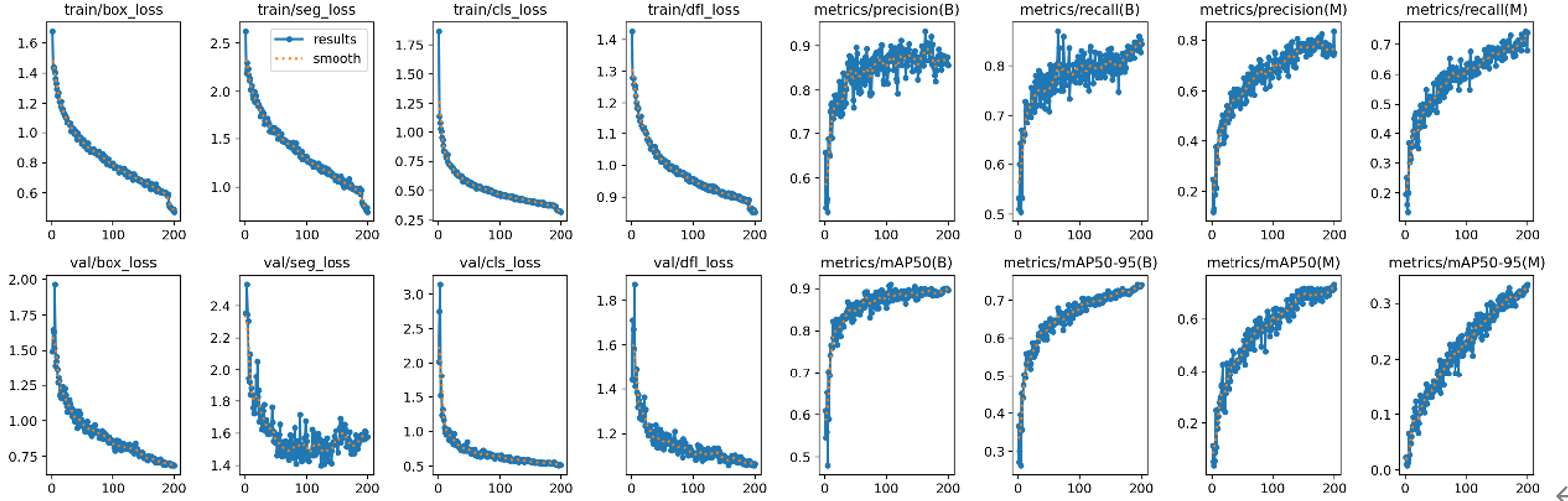 (圖四、損失與準確度圖表)
(圖四、損失與準確度圖表)
 (圖五、模型處理測試結果)
(圖五、模型處理測試結果)
乙、 箭矢落點分析 為了分析箭矢落點和入射角的資料,我們首先進行了箭矢落點和入射直線的特徵擬合。由於箭矢的顏色不同以及與靶及後方土坡的顏色和明度相似,我們結合了不同的顏色空間範圍進行篩選後,再使用CANNY輪廓檢測和基本的侵蝕擴張方法調適參數過濾出較為乾淨的影像進行累積機率霍夫直線偵測(HoughLinesP)。並透過不同閥值的調整和對線條間隙、重疊度的排除,進行箭矢偵測,由下圖六所示, 並在此記錄下直線的兩點:入射點和直線尾端,用以之後進行轉置
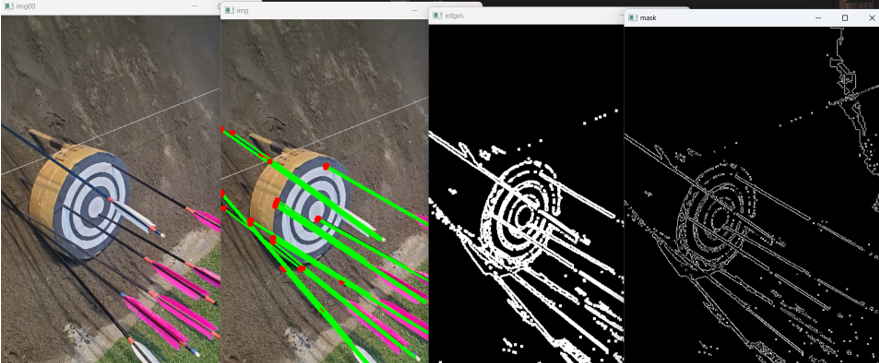 (圖六、圖片處理過程)
(圖六、圖片處理過程)
係箭矢的陰影會在直線判斷時干擾偵測結果,我們後續調整了不同的係數與各項處理的迭代數量並將重疊與間距拉大,得到以下圖七中的結果。
 (圖七、調整參數後結果)
(圖七、調整參數後結果)
丙、 座標轉置 由於拍照時難以拍到完全端正的靶,因此需要透過透視轉換將座標轉段至正座標,為此,我們決定先尋找靶框四個極點,再進行轉置運算重新建置新的座標系統
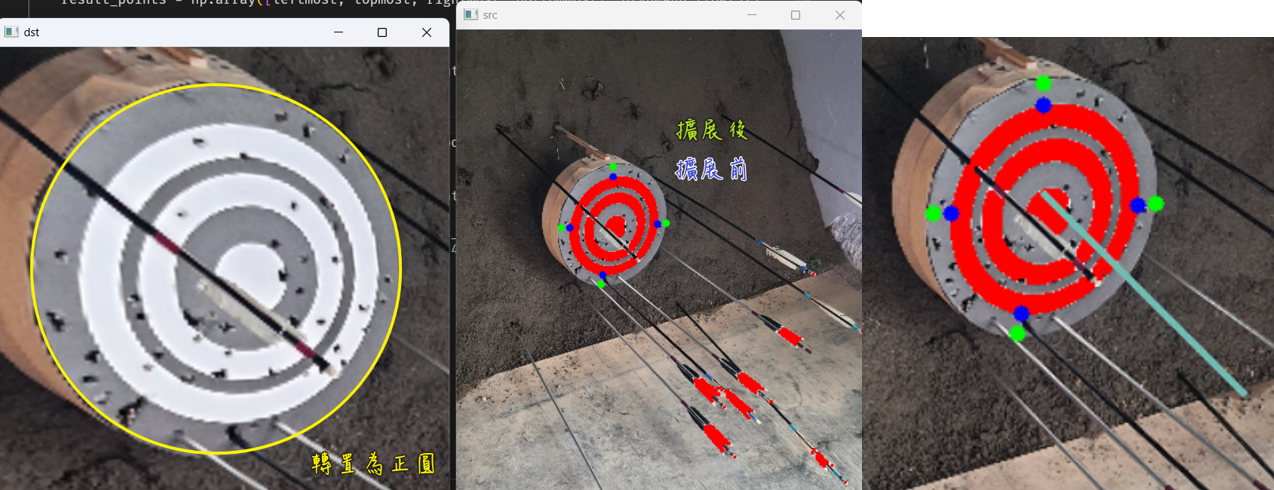 (圖八、靶面轉置)
(圖八、靶面轉置)
如上圖八所示,在找到四個極點後,可透過四個點構成的平面推導出其穿越靶面的法向量(上圖右邊淡藍色線),藉由三個點所連成的兩條線,將其視為向量進行numpy的cross運算即可得到(具體實踐可參考function.py中的image_process的imageprocess副程式)。
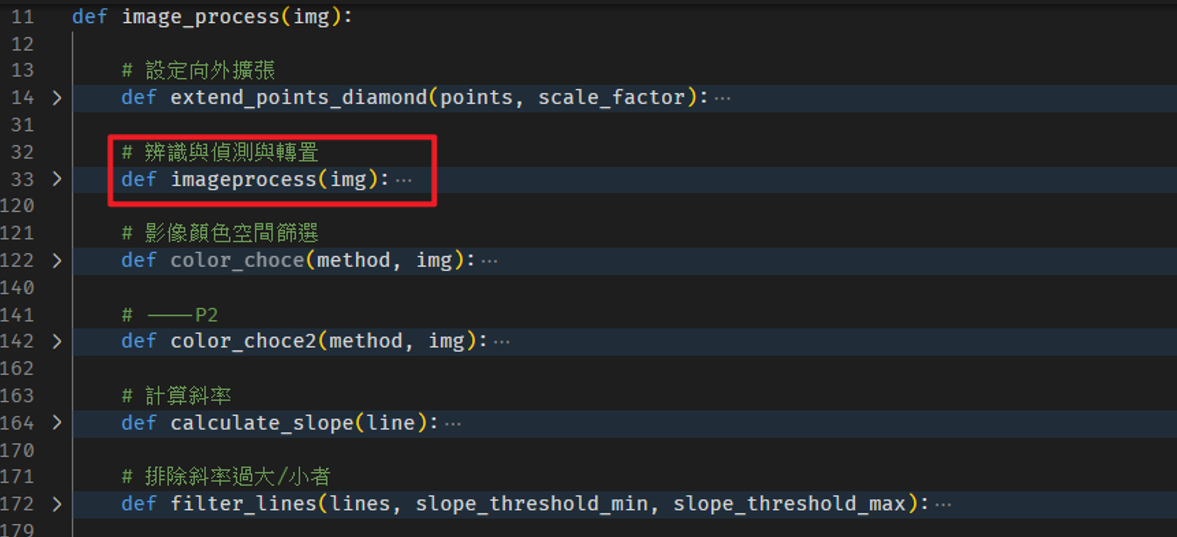 (圖九、影像處理程式細節索引)
(圖九、影像處理程式細節索引)
而透過四個極點和指定的新座標點之間的轉換,使用了cv2的findHomography方法,得到了透視轉換矩陣。至此,已獲得了繪製結果的三大重要因素: 原圖法向量、轉置矩陣和座標點(包含記錄直線的那兩點)。
丁、 重新繪製資料 由每張圖的三大因素資料可整理出繪製結果圖所需要的資料,合併上dynamoDB中用戶儲存的資料,接著利用pillow在指定座標加上文字(比如日期、弓具設定、場地設定資料等)以及重新計算的座標平面繪製中靶散布圖與分析中靶情況,最後針對法向量和箭矢直線向量取arctan(x/y)得到各自的方向向量(弧度)就可以計算箭矢和法向量的角度差θ,在結果呈現圖上該偏轉的靶的法向量已知,只需要針對該法向量進行θ角度的旋轉,即可繪製出入射直線,如下示意圖所示:
 (圖十,原圖與結果回傳圖對比)
(圖十,原圖與結果回傳圖對比)
三、 雲端技術 鑒於本地伺服器架置流程繁複且對於AWS雲端服務的好奇,本次專案的伺服器、資料庫以及API端口皆使用AWS服務完成。主要使用的服務是serverless的Lambda和API Gateway進行與LINEBOT SDK的後端路由處理和程式邏輯撰寫,同時結合了儲存容器S3和NoSQL雲端資料庫DynamoDB分別進行圖片資料與使用者設定值的CRUD動作。也在建置的過程中學習到相當多的經驗與技巧,包含Lambda中環境的打包與上傳和與深度學習模型的串接等,雖然十分有挑戰性但能夠學習在雲端上部屬的過程十分有趣。
參、 成果展示
在最終實際建置完成後進行了用戶實際使用情況與錄影進行展示,影片中有加速圖片處理之速度,實際回傳需等待15秒至30秒:
肆、 結論與未來展望
最後綜觀成果而言,有初步達成當初理想的結果與實現,也在座標獲取與計算方面進行了教育其更精準的結果,之後期盼朝著用戶箭矢的區分與提升整體程式進程效率的方向進行改善。
伍、 參考資料
[1] https://www.cnblogs.com/ybqjymy/p/12826850.html [2] https://github.com/roboflow/notebooks/blob/main/notebooks/train-yolov8-instance-segmentation-on-custom-dataset.ipynb [4] https://www.youtube.com/watch?v=wuZtUMEiKWY [5] https://www.youtube.com/watch?v=pFiGSrRtaU4&t=293s [6] https://docs.ultralytics.com/tasks/segment/ [7] https://ithelp.ithome.com.tw/articles/10282541?sc=pt